
使用socket takeover实现零停机时间发布
优雅退出(或者无损发布)是保证服务能力的重要手段。对于集群模式的服务,通常在服务进程前会前置一层代理(例如 nginx)来保证优雅退出过程中服务服务流量的切换。但对于单体服务,在不引入前置流量代理的前提下,实现优雅退出就会比较复杂,需要额外的技术手段进行辅助。本文将对单体服务的优雅退出方式进行讨论。
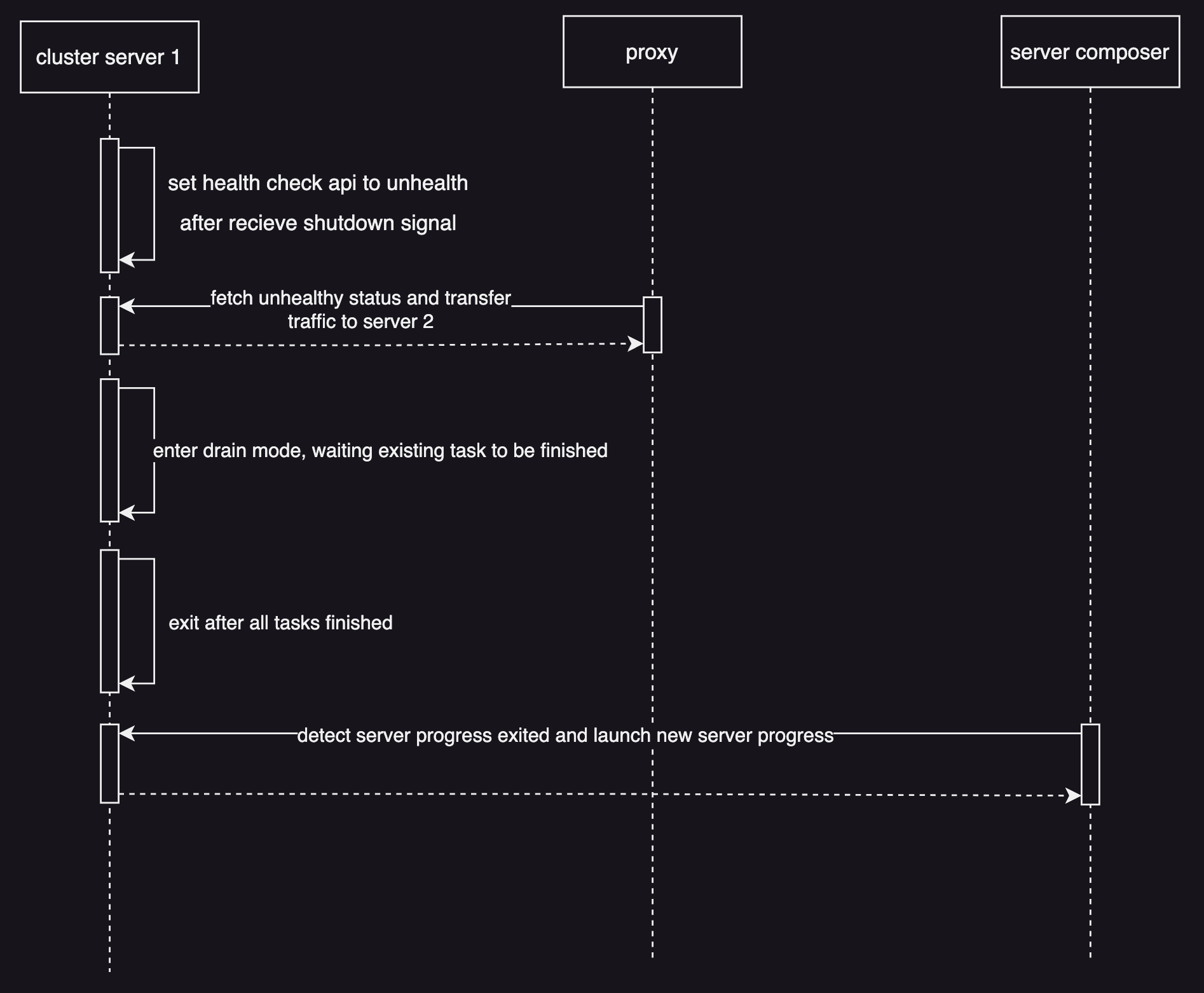
集群模式下服务优雅退出步骤如上图所示。该模式下老服务进程有较为充足的时间进入drain阶段(只处理存量任务流量),期间由代理通过健康检查接口探测到老服务进入下线状态,进而将流量转移到其它未下线的服务进城,保证了过程中服务能力的平滑过渡。
解决单点服务的优雅退出,核心需解决老服务退出、新服务启动阶段,进入流量(暂且称之为间歇流量)如何处理的问题。
Facebook 发表的Zero Downtime Release: Disruption-free Load Balancing of a Multi-Billion User Website这篇论文中,基于自身服务治理经验,总结了Socket Takeover、Downstream Connection Reuse和Partial Post Replay三种技术,以保证服务热升级。
- Socket Takeover
Socket Takeover技术需要使用SO_REUSEPORT参数,以相同ip/port同时启动新旧两个server。当新server启动成功后,旧server会停止接收新请求,并将处理中connection对应fd通过unix socket发送到新server,由新server接管并继续提供服务。新server会代替旧server应答上层LB的健康检查探针。 有以下highlight点:
- 最好在长连接场景下使用,否则overhead较大
- 新旧server流量切换依然强依赖于上层LB
- facebook主要使用socket takeover解决proxygen重启时,不同proxygen之间连接connection不中断的问题
- Downstream Connection Reuse
Downstream Connection Reuse技术主要用于解决proxygen重启时,上(Edge L7LB)下(MQTT Server)游与此proxygen连接如何通过转移保活的问题。 有以下highlight点:
- 只针对长连接
- MQTT Server在重连后,通过user-id获取对应上下文
- 用于解决proxygen重启时与上下游连接保活问题
- Partial Post Replay
Partial Post Replay技术用于解决后端Server重启时,与L7LB连接转移问题。当后端Server重启时,对于进来的请求返回特定状态码(379)和请求上下文,L7LB识别此状态码并将其重定向到其它后端Server继续完成服务。 Facebook三种技术手段均基于AF_INET设备,且依赖LB层进行切流,无法直接移植使用,但可以借鉴其中的一些思想。
Facebook 使用的 socket takeover 技术,依赖于内核提供的sendmsg系统调用。该系统调用可实现文件描述符 fd 的控制权在本地进程之间的转移。在优雅退出场景下,在旧 server 进入drain模式处理存量业务的同时,新 server 可接管已经监听的连接(conn,但 linux 系统中一切皆为fd),为间歇流量继续提供服务。
实现Socket进程间迁移和File Descriptor Transfer over Unix Domain Sockets这两篇文章做了较为详细的阐述,可参考阅读。
Facebook 论文中解决服务优雅退出问题时,使用了 AF_INET类型 socket 的SO_REUSEPORT选项,使得新老服务进程可以相同端口启动服务,并巧妙利用内核做了负载均衡。但该方式无法控制内核在老服务优雅退出期间持续向其投递新流量的问题,所以Facebook 论文中引入了负载均衡做流量控制。
该方案中同由于使用了内核提供的SO_REUSEADDR和SO_REUSEPORTsocket选项,但该选项只对AF_INET类型socket生效,对于AF_UNIX类型socket不适用。如果使用unix domain socket作为网络通信设备,需调研其它方案。
对于使用unix domain socket(以下简称 uds)类型的服务,需在原本的业务 socket 外,引入额外的 upgrade data socket作为升级过程中交换升级数据的通道。
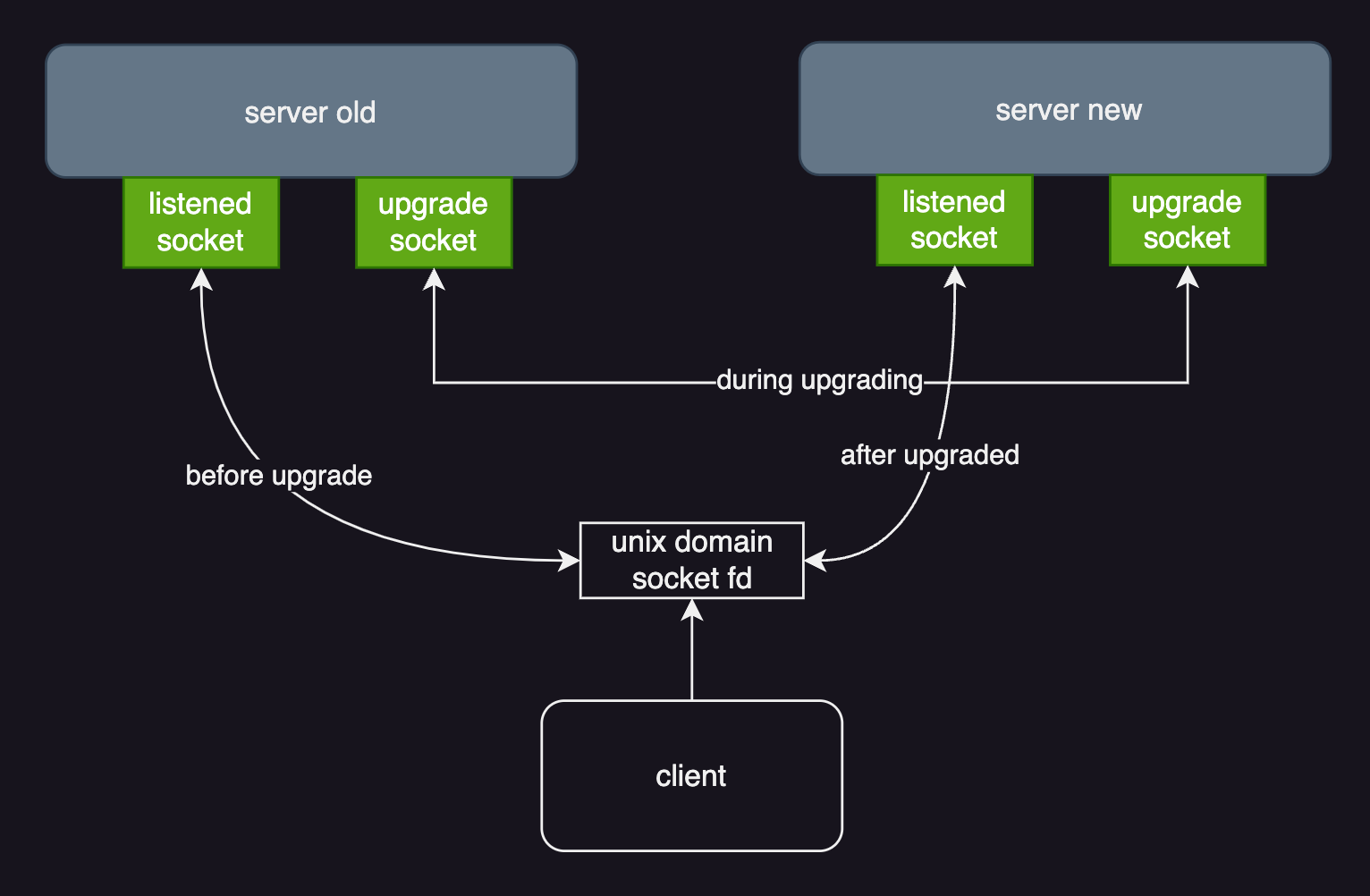
如图所示,升级前uds client 与server 正常通信。升级时,通过 socket handover 技术将监听的 socket 对应的 fd 文件转移到新启动的server中,后续服务能力由新server提供。对于client侧,整个升级过程是无感的。
上述流程保证了升级过程almost无损,但还不是全无损的。当新server启动后,新进入的流量可由新server正常提供服务,但此时老server中的在途流量会因为老server中fd的close导致无法回包。为了解决此问题,需要同步新老server的升级状态,将老server处理完的在途(in-flight)流量,也能够同步到新server中,由其返回给client。
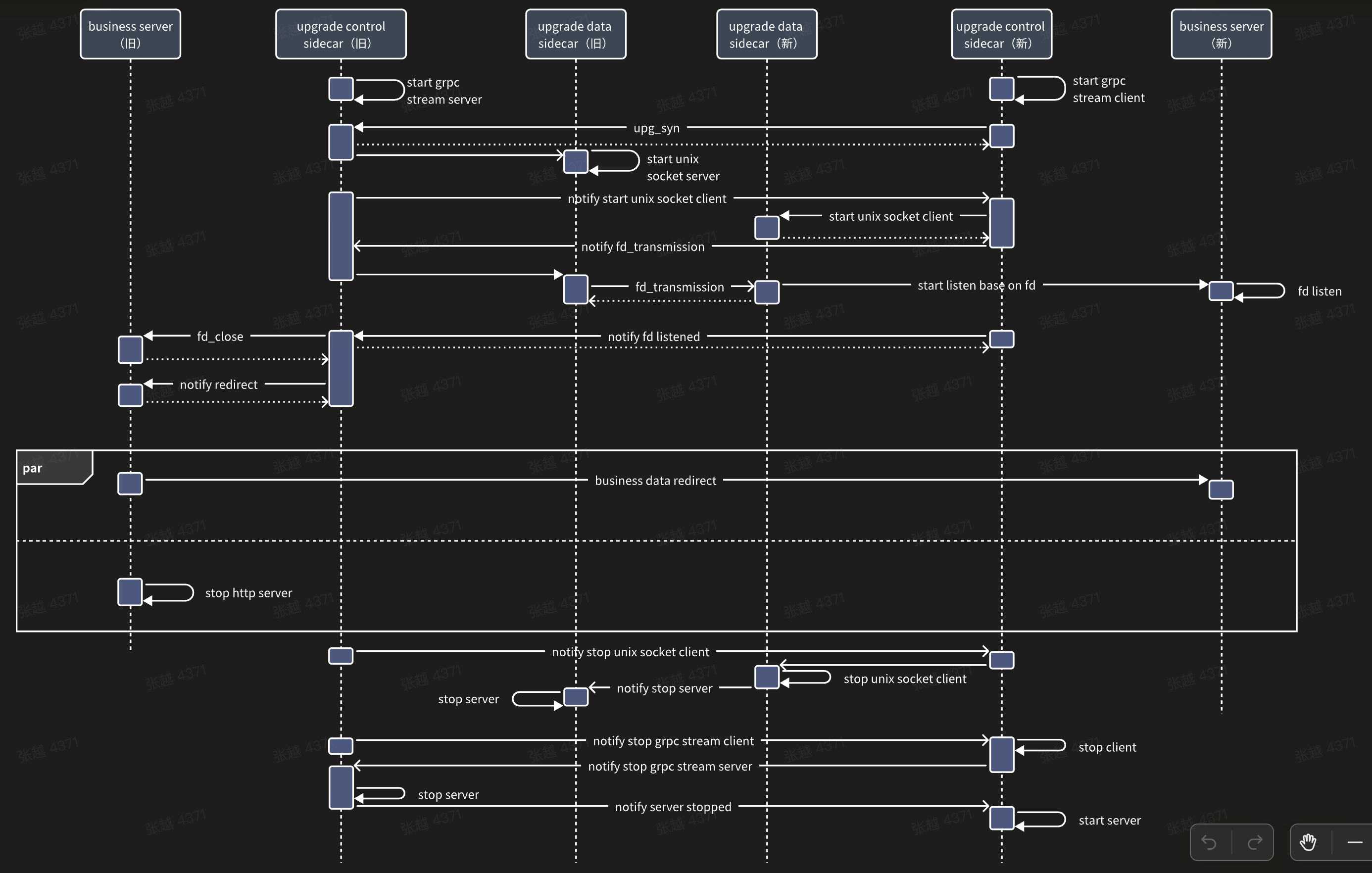
上图所示的升级链路中,引入额外的upgrade control socket作为同步新老server升级状态的通道,保证能够在合适的时机将老server的在途流量同步到新server中。全无损升级中新老server的状态机如下图所示。
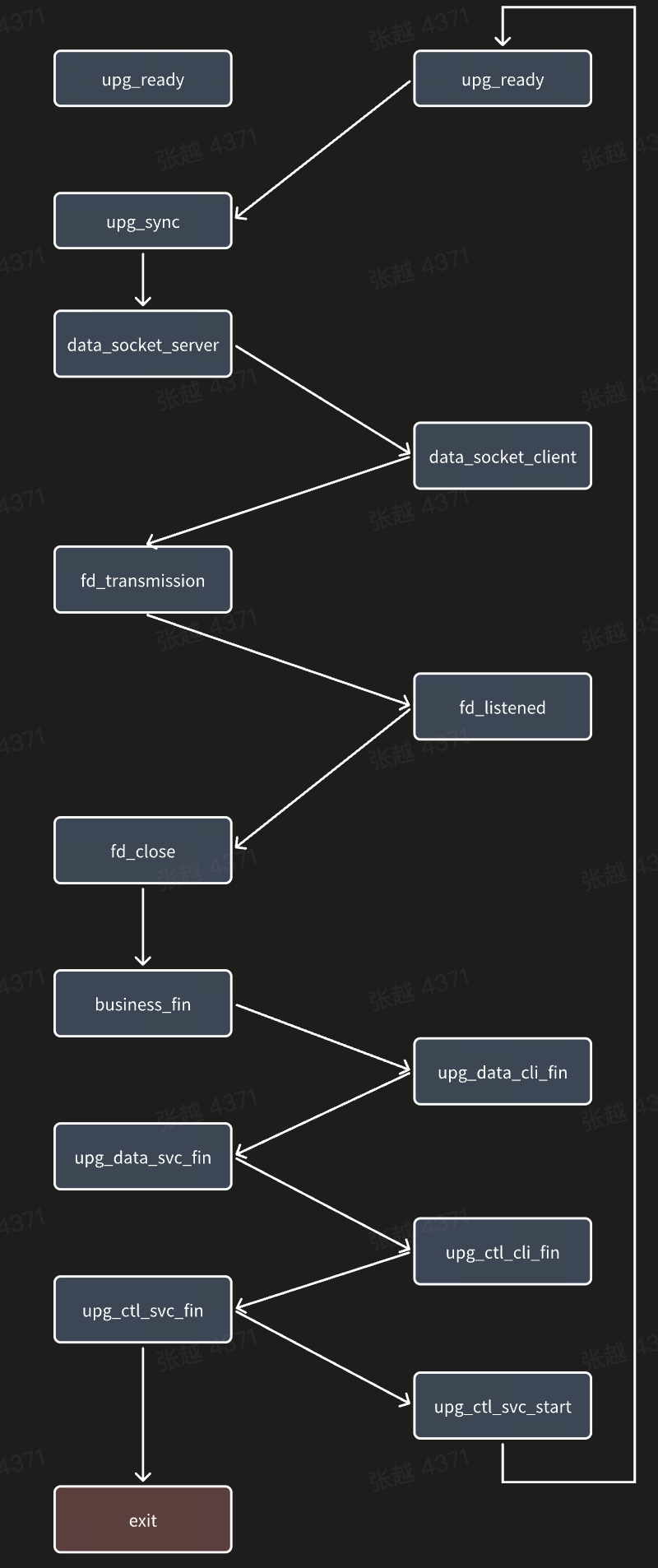
个人仓库zero-downtime-upgrade提供了基于socket takeover技术实现的服务热升级demo。但考虑到实现复杂度,demo仅对client端无感升级过程进行验证。下面几点需要highlight下。
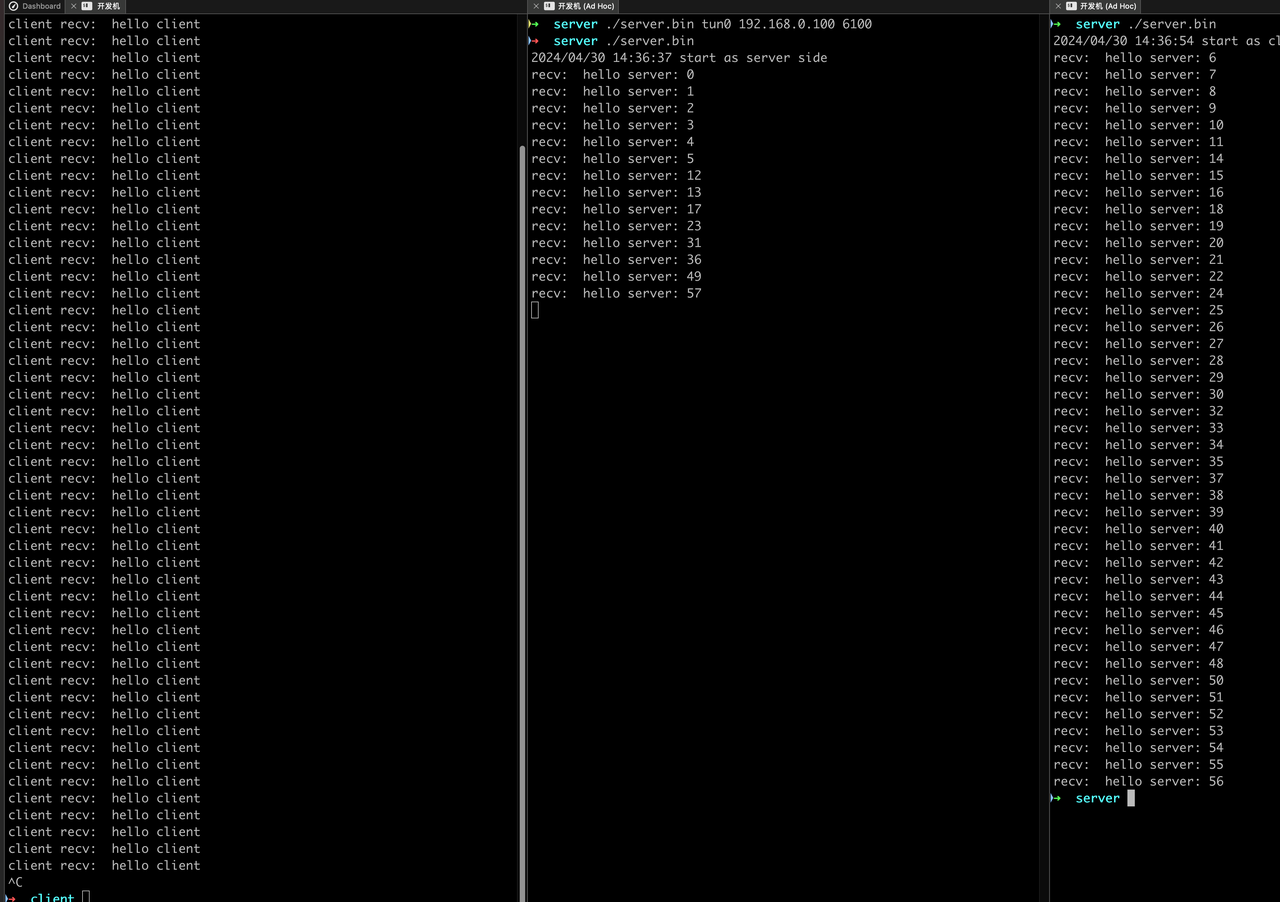
- fd被新容器监听后,如果老容器不close会怎样

如图,如果在新容器监听fd后,老容器不关闭已监听fd,则两个fd会以负载(不一定)均衡的方式提供服务,该模式与AF_INET使用SO_REUSEPORT选项效果类似。如下:
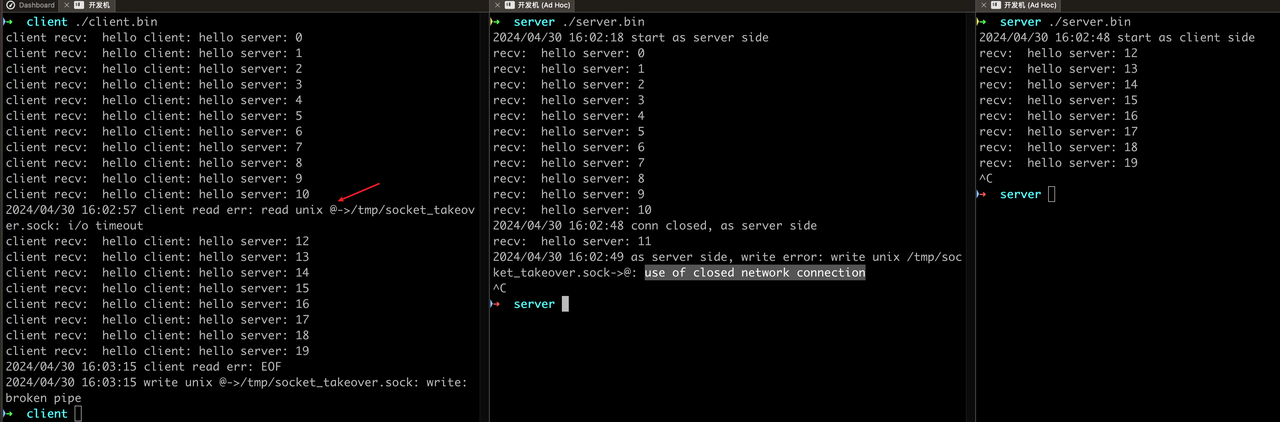
- 老服务关闭监听fd后,处理中任务如何任务可否继续通过原fd继续

该问题讨论将图中红框部分省略后,内核是否有能力自动完成处理中任务的发送。与预期相同,任务处理完成后,通过已关闭fd发送响应,报use of closed network connection错误,对应处理中任务丢失。
为了解决此问题,也尝试通过shutdown系统调用,传入SHUT_RD选项,通知老服务停止读取新conn,但保留处理中response的传输能力。最终发现此方法不可行,shutdown在关闭conn时与close不同,不会考虑file description的引用数,而是暴力清理。会导致client和传输到新容器的fd无法继续工作。即使通过dup系统调用生成新fd发送给新容器,但由于新旧fd的底层的file description是同一个,也会导致已有连接关闭。